
Regardless of where your organization stands in its digital transformation journey, GRAX enables data-driven decision-making through data reuse. GRAX History Stream was built to align tightly with how data processing works in the modern enterprise. GRAX leans on well-established and understood formats, frameworks, and conventions to facilitate out-of-box connectivity options that can unleash the value of your historical Salesforce application data.
Let’s take a closer look at reusing historical data in the well-known data warehouse, Snowflake. History Stream eliminates API and ETL/ELT challenges by using the industry-standard Parquet format. This is an excellent example of how GRAX was built to leverage native, scalable, out-of-box patterns to make cloud application data readily available and consumable by platforms like Snowflake.
Solution Overview
The data pipeline described below involves the following high-level components:
- Set up GRAX History Stream and enable GRAX backup and/or archive jobs
- Create a target Snowflake table
- Create a Snowflake External Stage that points to the data source (GRAX S3 History Stream location)
- Create a Snowflake Pipe
- Configure S3 event notifications to notify and trigger the Snowpipe data loads into the table
Set up GRAX
First, enable History Stream for the desired Salesforce objects. As GRAX backup and archive jobs execute, History Stream will automatically create Parquet files in the designated S3 bucket. With a few clicks, you’re set up in GRAX to drive downstream consumption into Snowflake.
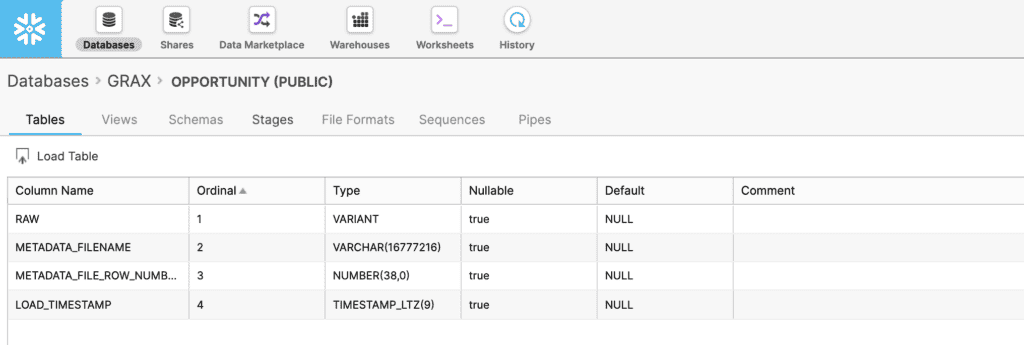
Create a Snowflake Table
Second, create a table within a Snowflake database. The table will store History Stream data for a given Salesforce object. In this example solution, we will have Snowflake read the GRAX Parquet data into a single variant column, which Snowflake offers for storing semi-structured data with flexible schemas. When dealing with Salesforce data, schema drift is a very common occurrence, so this approach will not force us into a rigid structure. Instead, we will load the data from GRAX into Snowflake adopting a pipeline more akin to a modern ELT process.
Be sure to understand all of Snowflake’s recommendations around these field types.
Create a Snowflake Stage
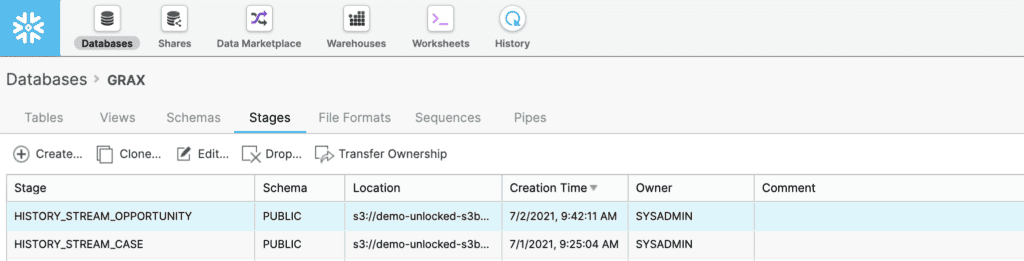
Next, create an external S3 stage in Snowflake. An external stage specifies where the GRAX History Stream data is stored. This is how Snowflake knows where to consume GRAX data. In this example, we are using AWS S3, but this can also be based on Azure Blob Storage.
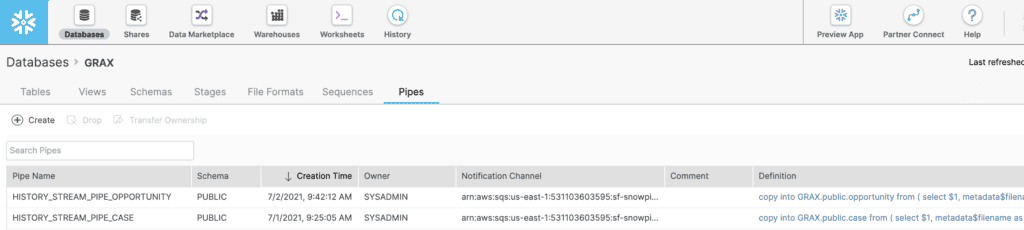
Create a Pipe
Snowpipe is Snowflake’s continuous ingestion service, which monitors the stage and loads the data into the table as soon as it’s available. Additionally, it provides a notification channel that we can use to trigger the process in S3. We are essentially defining a COPY INTO statement used by Snowpipe to load data from the ingestion queue stage into the target table. We can now start to see how GRAX works seamlessly with native cloud services like Snowpipe with clicks, not code. The idea is not to force your organization into developing or paying vendors for hard-coded and difficult-to-manage custom connectors.
Configure S3 Event Notifications
One benefit of leveraging Snowpipe is that it provides an SQS Queue that facilitates S3 event notifications to trigger the process. After creating the pipe in the previous step, you can run the SHOW PIPES command to find the ARN of the SQS queue, which Snowflake will refer to as the Notification Channel. From there, navigate to the S3 bucket and create an event notification, selecting the SQS queue as the destination and copying in the ARN found in Snowflake. Data teams are free to configure the S3 notification event types per requirements, triggering based on prefix or suffix.
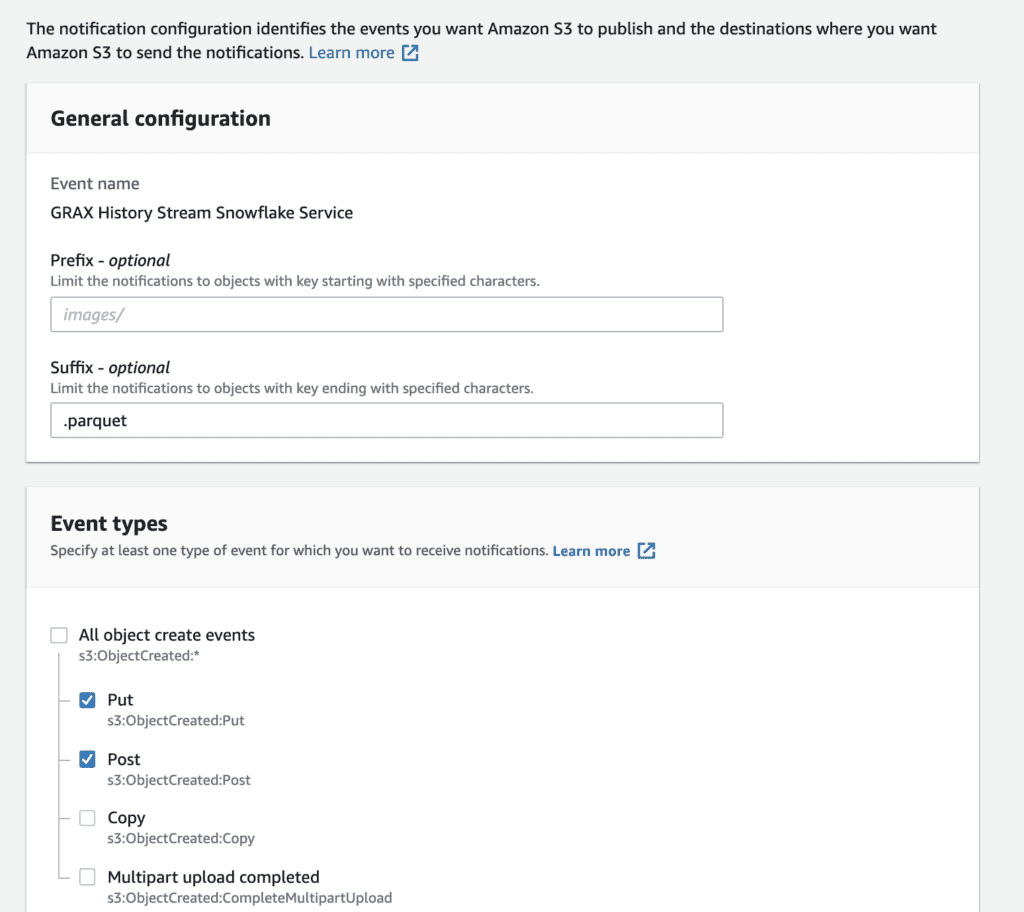
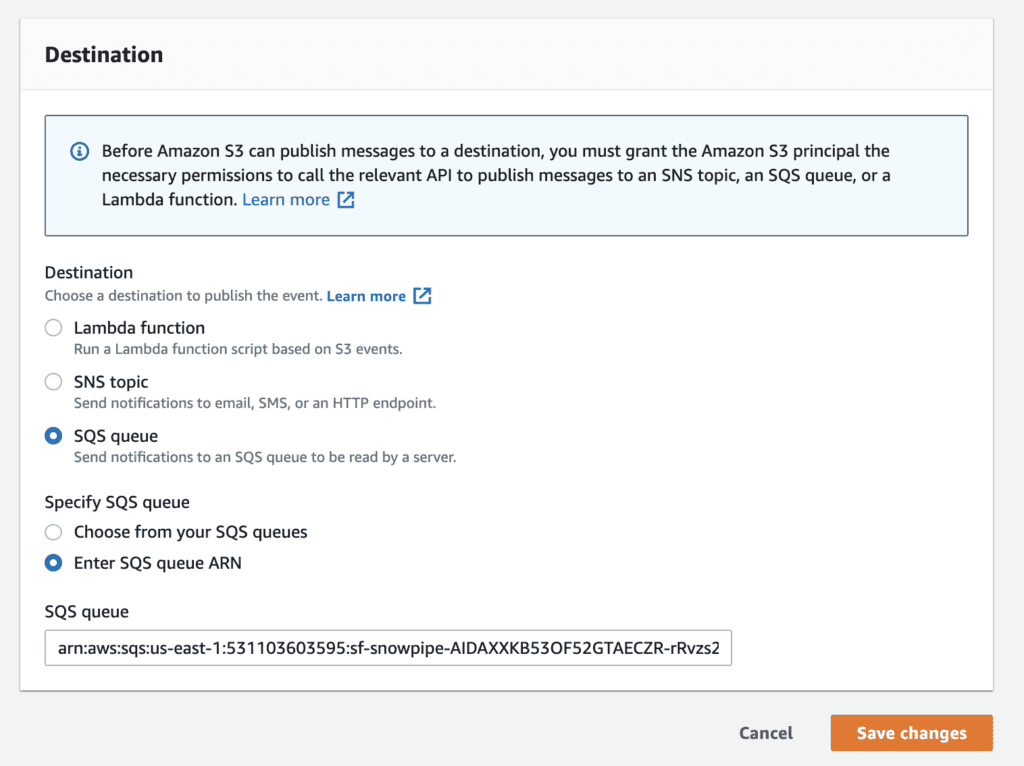
Transform the Loaded Data As Needed
We’ve now configured everything needed and have an example data pipeline ready to go! Once the data begins flowing into Snowflake, your organization can now focus on setting up transformations, procedures, and views to make that data available to business users for reporting. Analytics engineering teams can take it from here, serving as the bridge between data engineers and data analysts. Be sure to reach out to GRAX for more information and examples of historical Salesforce data driving business intelligence in tools like Tableau, PowerBI, and Amazon QuickSight.
Conclusion
Regardless of your organization’s data architecture, owning and unlocking your SaaS application data in a way that conforms to the existing data strategy is critical in reducing time-to-value and increasing adoption. This could take the form of analyzing historical patterns in Salesforce Sales Cloud opportunities, Salesforce Service Cloud cases, or any other critical and evolving business data. As your enterprise seeks to become more data-driven and competitive in the market, it is no longer enough to just backup, archive, and restore Salesforce data. Maturing your organization’s data strategy to move up the data value curve becomes critical. With GRAX, you can enable your organization for analytics, AI/ML, and more by using your historical data in your downstream platforms, with clicks, not code.
See GRAX History Stream + Snowflake in Action
Please note that the patterns detailed in this post are not meant to be instructions but rather examples of what is possible to do with GRAX. With the help of data engineers or data analysts, they can help you better understand what will work best within the context of your enterprise’s data architecture. Ready to discuss your specific use case? Get in touch.

