About this talk
Watch this GRAX demo video to see how easy it is to take control and ownership of your Salesforce data with GRAX:
- Backup all your Salesforce orgs
- Keep archived Salesforce data 100% accessible in production
- Capture up to every single change
- Pipe and reuse your Salesforce data anytime, anywhere
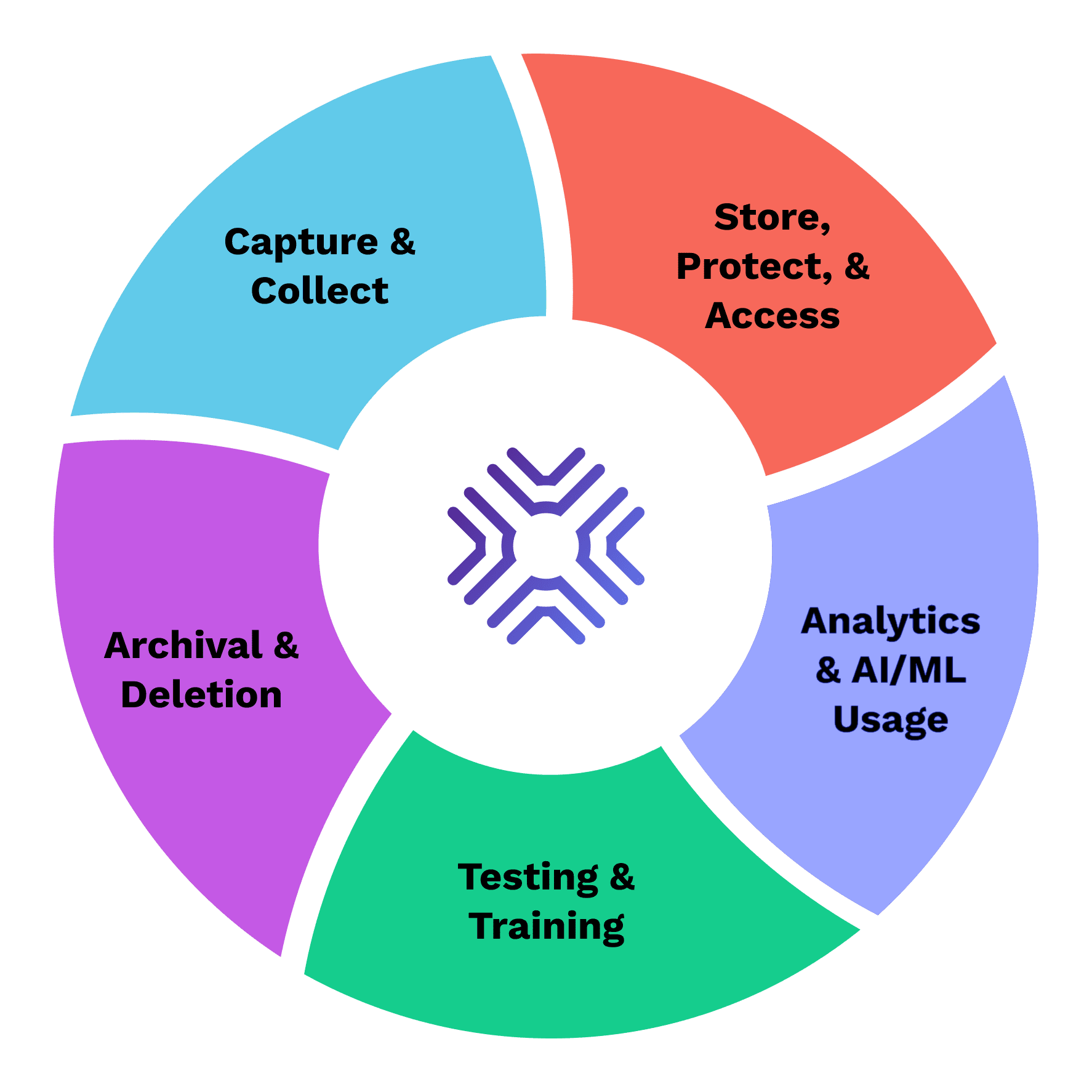
GRAX is the new way that businesses preserve, recover, and act on their historical data. GRAX captures an irrefutable, recoverable record of your Salesforce data, storing it in the customer’s own environment and making it available for analytics, data warehousing, AI/ML, and more. This approach creates a modern, unified data fabric that helps companies protect, understand and adapt to changes faster in their business.
Complete the form to watch the GRAX demo video of how our solution can effortlessly preserve, recover, manage, and analyze your historical Salesforce data - with no code required.