
Since its earliest days, GRAX has been about more than just backup. What we’re really about is capturing historical data.
While the first priority for our customers is to protect their mission-critical Salesforce data, most of them are increasingly looking to take control of their historical data and reuse that history throughout their enterprise for a variety of use cases ranging from advanced business analytics, long term storage in data lakes/warehouse and even app development.
Today, we are taking a significant step towards radically simplifying these use cases for our customers by launching GRAX History Stream™.
This exciting new feature allows GRAX customers to easily turn on the downstream push of GRAX stored data for selected objects. Not just for the latest version of Salesforce data but for the entire historical data set captured by GRAX. History Stream fundamentally raises the bar for what you can do with your Salesforce data.
At a high level, here’s how it works:
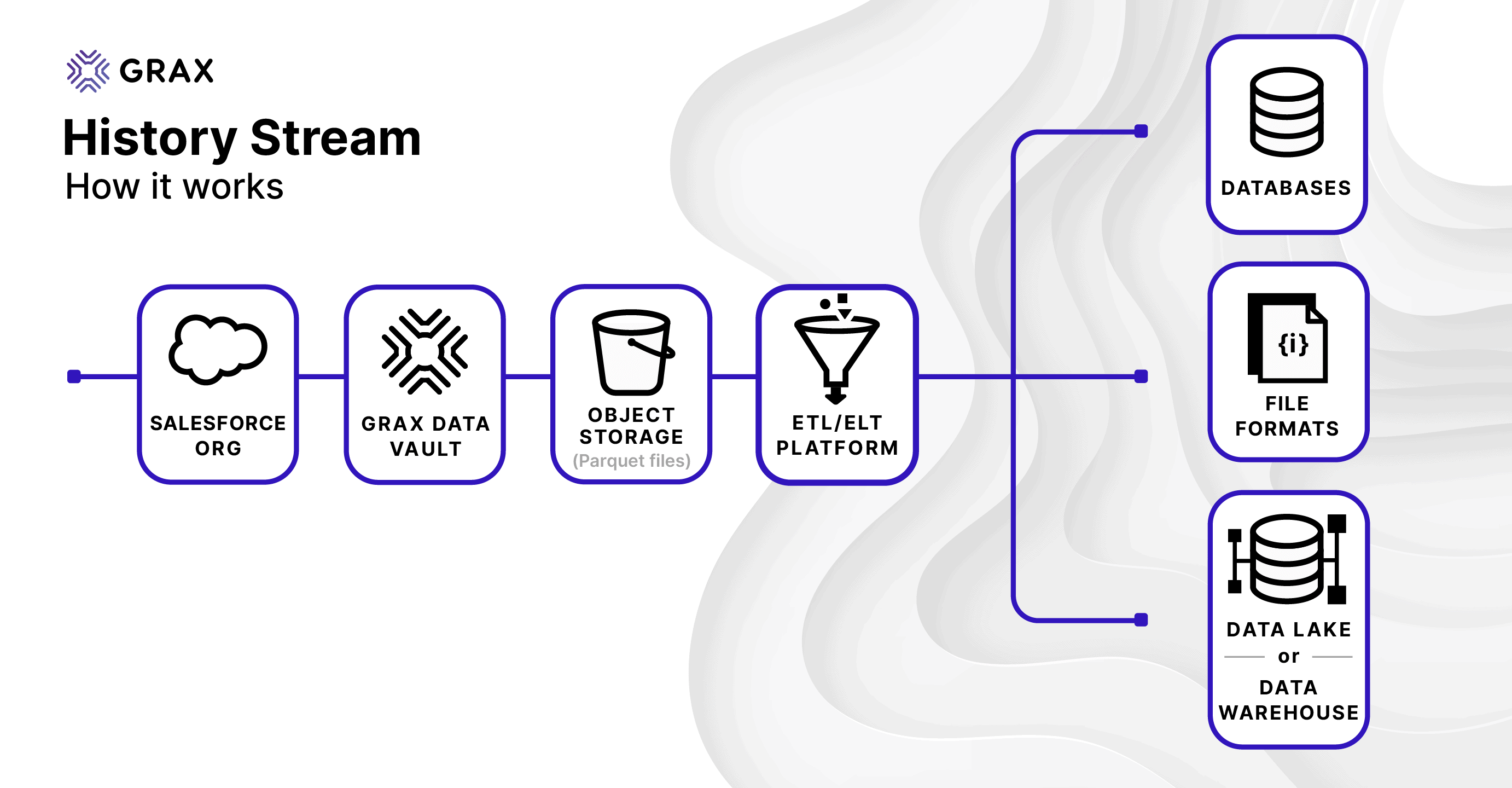
We built this to align tightly with how ETL and data processing typically works in the modern enterprise. Our goal was to introduce as few proprietary concepts as possible and lean heavily on well-established and understood formats, frameworks, and conventions.
- GRAX ♥️ Cloud Object Stores. Just like the GRAX Data Vault, History Stream utilizes the highly scalable object stores, built into the very fabric of the major public cloud platforms – Amazon AWS, Microsoft Azure, and Google Cloud Platform – for data delivery. Using an object store like Amazon S3 rather than a queueing platform like Kafka or Kinesis keeps things simple for consumers. It allows us to leverage the well-understood cost model and massive read scalability of these services.
- We write data into Parquet. Different customers want different formats, but we settled on Parquet for its combination of compatibility, compression, and ability to carry schema/metadata. That last bit is crucial with Salesforce CRM data since it’s a dynamic platform where schema frequently changes over time. Managing schema changes is a caveat that’s significantly tougher to deal with if all you receive is CSV data, for example.
Here’s a slightly more specific view of what this looks like in AWS:
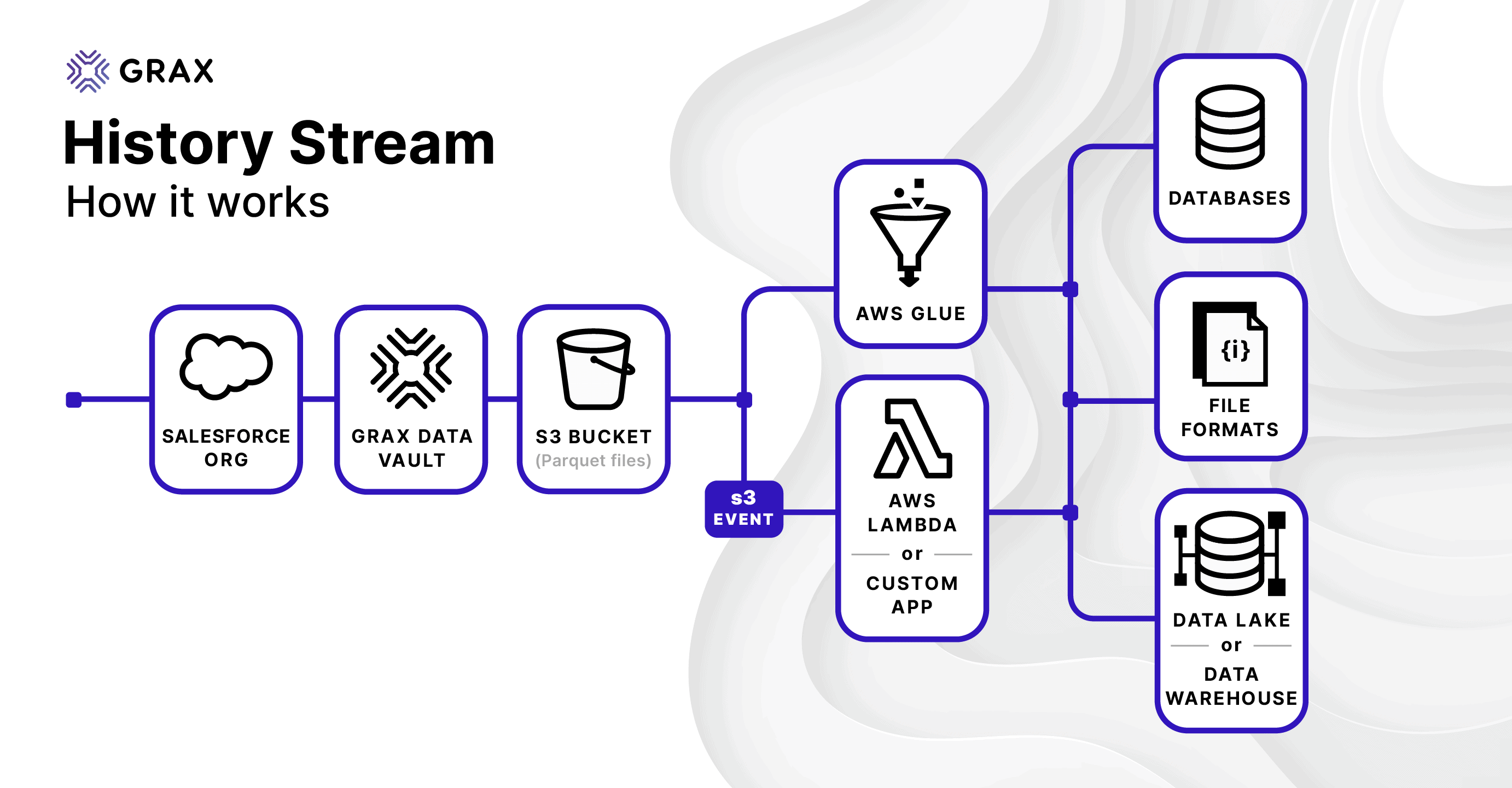
A key concept here is making things as easy as they can be, standing on top of all the great services and technology primitives that exist in AWS:
- Our data structure and partitioning scheme works out of the box with AWS Glue. Besides being a fully-featured ETL Platform, Glue is important because of its integration with other AWS data services like Athena and QuickSight. These services can use Glue’s metadata catalog directly to discover data without any further configuration. With GRAX History Stream, all you have to do is point Glue at your Parquet directory, and it just works – no coding required.
- Some customers will want to highly customize transformations in flight, and the Amazon S3 Events + Amazon Lambda approach supports that. While most are going to want a no-touch, set-and-forget data pipeline, some will want to highly customized transformation and processing of their historical data. Because it’s just files in S3, you can get notified when new data is ready using standard S3 events. You can easily subscribe to these for serverless processing with AWS Lambda, but really any custom application logic can easily be attached.
So how do you get this thing turned on? Fortunately, it’s simple. Eventually, we will have a self-serve UI in the app for it, but for now – while the feature is still in limited release – simply make a list of the objects you’d like to push downstream, and contact your GRAX Account Manager to have it turned on.
That’s it. The GRAX History Stream™ is a simple, but extremely powerful addition to the GRAX product suite that allows you to easily access the entire wealth of your Salesforce data history for use in virtually any platform.

