
It would be difficult to find a high-level manager or a business owner who does not understand the value of data in a business environment. Not only can data help with making important business decisions, but it can also be used to analyze internal processes, study competition, and even gain a better understanding of what their customers need.
Working with information in some way is now an irreplaceable part of almost any business process at any level. This kind of variety also leads to an abundance of tools that can store, process, and analyze information in different ways. Customer Relationship Management solutions such as Salesforce are one of many examples of such tools, made to assist with customer interactions and collect customer data.
Yet, data storage can be expensive in environments that were not made to handle large data masses to begin with. Salesforce has this exact issue, with strict limits on internal data storage and extraordinarily expensive capacity expansion packages. Luckily, general data storage tasks (as well as data analysis) can be handled by tools such as cloud data warehouses or relational databases.
In this article, our primary example of a cloud data warehouse is Amazon Redshift. Additionally, the topic of integration in this context is above and beyond the regular data exporting process, considering how Redshift can analyze information with ease.
We can start our journey toward finding out all of the nuances of integration between Salesforce and Redshift by providing detailed definitions of what both of these platforms are.
What is the Salesforce and Amazon Redshift Integration?
Understanding the Salesforce Data Structure
Salesforce is a cloud-based customer relationship management platform that was originally aimed at helping businesses with customer and lead management tasks. Salesforce’s capabilities have expanded significantly over the years, with field service management, analytics, lead generation, marketing intelligence, and many other features that it can provide now. It is also easily integratable with a large selection of other platforms and services, including Slack, Evergage, Tableau, ClickSoftware, and many others.
The most noteworthy capabilities of Salesforce are presented in packages of sorts, categorized as follows:
- Service Cloud alleviates the total customer service experience that the business can provide to its clients. This includes personalized support through many communication channels, as well as self-service options, AI-powered chatbots, etc.
- Marketing Cloud covers the capability to manage personalized marketing campaigns at scale, engaging with potential customers using a combination of social media advertising, targeted emails, and automation workflows. Campaign performance analysis and audience segmentation capabilities are also included here.
- Community Cloud allows for the creation of branded online communities for customers, partners, or employees. Communities foster mutual support, knowledge sharing, and collaboration within themselves while also enhancing customer loyalty, facilitating partner engagement, and enabling advanced self-service capabilities.
- Sales Cloud offers many capabilities to track and manage the general sales pipeline. It can also automate tasks, gain valuable insights from customer interactions, and so on.
- Commerce Cloud makes it significantly easier to create seamless customer e-commerce experiences. It usually covers secure transactions, product catalog management, online store creation, and subsequent optimization of the overall shopping experience for different device types.
Overview of Amazon Redshift as a Data Warehouse
Amazon Redshift is a cloud-based serverless data warehousing solution from AWS. Being a fully managed service, Redshift covers the entirety of infrastructure and maintenance tasks, making more time for the end user to analyze data and derive useful insights from it. Redshift is a great option for handling large data masses, as well, making it a great option for both semi-structured and structured information from Salesforce or other sources.
Due to its inherent nature as an AWS product, Redshift can also easily be integrated with Amazon S3, AWS Glue, Amazon Athena, AWS Data Pipeline, AWS Quicksight, AWS Sagemaker, and many other Amazon products or services. Some of the most noteworthy capabilities of Redshift are:
- Extensive scalability. Redshift can scale its own size for companies that experience rapid growth periods by simply increasing or decreasing the total number of nodes in the cluster. The addition of more nodes also improves Redshift’s total processing power, providing faster query results.
- Massive Parallel Processing. Redshift can easily handle processing across multiple nodes at the same time, greatly improving the total performance of queries and other data-related tasks. Simultaneous processing in such environments is somewhat rare, making it a substantial advantage of this service.
- Advanced Query Optimization. The platform also uses sophisticated query optimization techniques instead of just relying on sheer computing power. Query rewriting, intelligent data distribution strategies, and dynamic query execution plans are just a few examples of such techniques. Redshift can optimize every single query and data distribution rule, selecting the most efficient execution method in each situation separately.
- Columnar Storage. Columnar is a format that Redshift uses to store information in, it is often considered one of the best options for fast analytical workloads. Columnar storage can selectively access columns that store the required information, which makes them stand out a lot when compared with a more traditional row-oriented storage approach.
Benefits of Integrating Salesforce with Redshift
An integration of Salesforce with Amazon Redshift offers a number of substantial benefits, of which we can discern three of the most notable ones:
- Improved data management is achieved by removing the need to transfer data from Salesforce to Redshift manually every single time. The combination of time savings and lower data error risk is a substantial advantage on its own.
- Real-time synchronization of any changes, making sure that all data in Amazon Redshift storage remains up-to-date after every single change in the Salesforce environment.
- Better data analysis is made possible by the overall technological advancement of Amazon Redshift as a powerful data warehousing environment. Redshift’s high-grade performance is an immense advantage to any data analysis processes that need to be performed on Salesforce data, gaining actionable insights at record speed without losing accuracy.
- Convenient data preservation is a necessity in many cases due to Salesforce’s somewhat strict data retention rules. Older data gets archived or even purged on a regular basis in Salesforce, and the storage itself there is very expensive. This makes Redshift an incredibly convenient alternative that is both cheaper and more convenient (especially considering how some compliance rules necessitate data storage for certain periods for auditing purposes), while also opening up a lot of opportunities for specialized solutions like GRAX to provide their data management services in a convenient manner.
How to Manually Load Data from Salesforce to Redshift?
It would be fair to say that third-party Salesforce tools are the most convenient way to integrate Salesforce and Redshift environments. In order to add more weight to our argument, we would like to start by providing a detailed explanation of how these processes work natively. Our first example is going to be the manual data exporting process that cannot be automated by normal means.
Exporting Salesforce Data Using Data Loader Export Wizard
Data Loader is a client application from Salesforce that offers bulk import or export capabilities for data. It can handle up to 5 million records at a time, but it is only available to users of Enterprise, Performance, Unlimited, and Developer editions of Salesforce.
In order to export information from Salesforce to Redshift, our first step would be to download the CSV file from Salesforce created by Data Loader. Here is how this can be done:
- Open Data Loader and click the Export button.
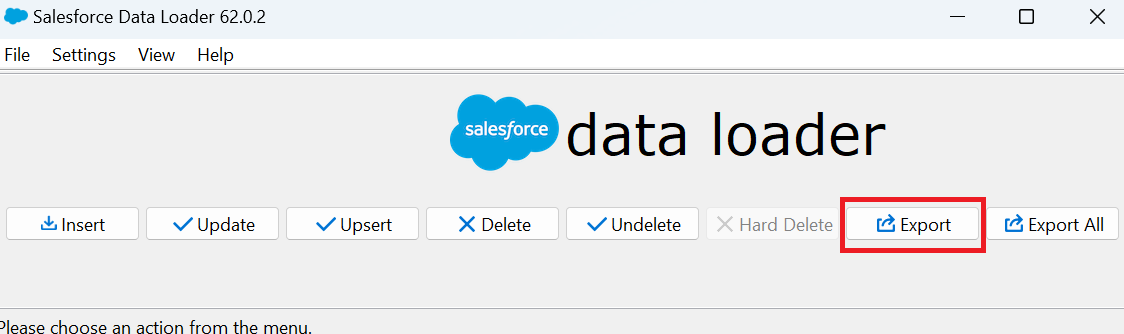
- Input your Salesforce credentials and Log in.

- Choose the Salesforce object that you want to export information from.
- Enter the name for the future CSV file and click Next (it is also possible to choose and rewrite one of the existing CSV files).
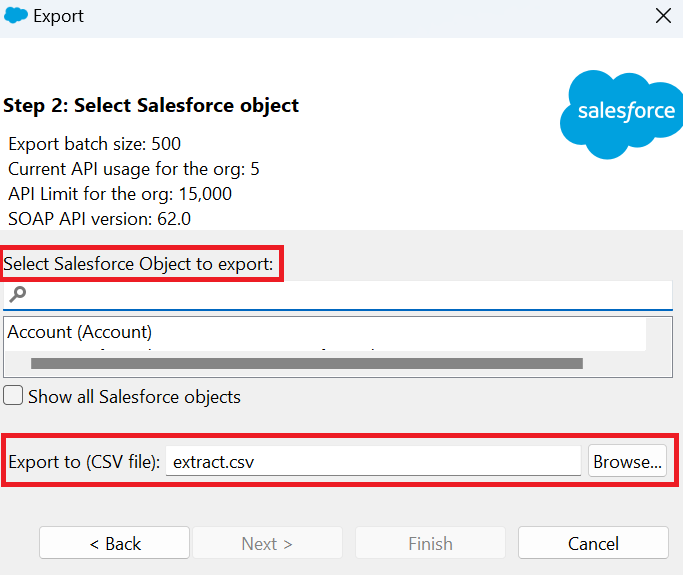
- Create a SOQL query (Salesforce Object Query Language) that specifies the fields you want to export, as well as exporting conditions, filtering rules, and so on.
- Finish the setup process and confirm the creation of a CSV file by clicking Yes afterward.
- You should now see the current status of the CSV file generation.
- Once the process is completed, you should be provided with a separate confirmation window that notes down the results of the process.
- Clicking on View Extraction makes it possible to immediately view the newly generated CSV file if you wish.
Moving Data from Salesforce to Amazon S3 Bucket
The next step in this process would be to upload the CSV file in question to Amazon S3 Bucket. Here is how this process can be performed:
- Open the Amazon S3 Console and select the Create Bucket option.
- Select a name and a region for your S3 Bucket, and click Create to proceed.
- Once created, choose the bucket in question, click on Actions and select the Create Folder option from the drop-down list.
- Name the folder you want to create, confirm your choice, and open the folder in question by clicking on it once again.
- Select the Files wizard option and click on Add Files to proceed.
- In the next window, select your newly created CSV file and choose the Start Upload option to finish this step of the process.
Using COPY Command to Import Data into Redshift
Now that we have all the information from a CSV file loaded into an S3 bucket, it is time to establish a connection between the bucket and Redshift’s platform. As the title suggests, the COPY command in Amazon Redshift is responsible for loading data. A typical command sequence looks like this:
COPY table_name [ list_of_columns ] FROM source_of_information CREDENTIALS login_pass_combination [options]
Here are the most important values in this version of a COPY command:
- table_name is the table that the COPY command would target in the data source.
- list_of_columns is only necessary if you want the fields from the source data to be inserted in a non-standard order; a column list is provided using all of the column names separated by commas.
- source_of_information is the target location from which the COPY command would draw the data in the first place.
- login_pass_combination are the AWS access credentials that are necessary to access the AWS resources for data storage purposes.
Generally speaking, this method has a lot of disadvantages and is only suitable for case-specific data exporting situations that would be difficult to manage with other means. The complete lack of synchronization capabilities is the most notable issue here, along with the time limitation of the Data Export tool’s capabilities, a substantial potential for errors in transformation or copying processes, and so on.
How to Connect Salesforce to AWS Redshift with AWS Glue
Following the purpose of the previous section, we would also like to showcase one of the common native integration methods for Salesforce data to be synchronized with a Redshift data warehouse. This particular method relies on AWS Glue and a number of other features that are built into Salesforce or Amazon Redshift.
It should be noted that this section is going to be much less detailed than the previous one due to the highly personalized nature of these operations with API interactions, custom commands, and so on.
Initial Setup for AWS Glue and Salesforce Connector
The foundation for integrating Salesforce data into Redshift lies in the Salesforce Connector, which can be found in the AWS Marketplace. This connector can be installed from the aforementioned marketplace onto the Redshift cluster with relative ease.
Once installed, the connector must be configured with an appropriate login-password combination (as well as potential security tokens) in order for it to be able to connect to the Salesforce instance.
Before proceeding, it is highly recommended that the connector’s capabilities be tested when contacting the Salesforce instance. That way, you can avoid issues with connectivity in the future.
Additionally, you would also have to prepare an AWS Glue Data Catalog to store your data in the future. This includes creating a new database, configuring a crawler that would be able to discover and catalog Redshift tables, and providing the necessary connection details.
Setting Up Data Pipeline for Data Transfer
Once the connection between environments is established, it is time to begin working on configuring the data pipeline for data exporting purposes. It can be created by configuring external schemas and tables using either the AWS Management Console or some sort of SQL client.
The external schema is created using the capabilities of Salesforce Connector, while the external tables are configured in Redshift to map the Salesforce objects that you would like to access, defining the structure and target location of each object.
Once both schema and tables are established, it is highly recommended to run sample queries for data fetching from Salesforce into Redshift to ensure complete connectivity between the two.
Automating Data Synchronization in Redshift Cluster for Salesforce Data
In its current state, the connection between Salesforce and Redshift can only exchange data manually. However, it can be automated with relative ease:
- Set up a data pipeline with either AWS Glue or any ETL tool.
- Configure the data pipeline to extract information from Salesforce and load it into the designated Redshift tables.
- Automate said pipeline to run at regular intervals, ensuring consistency and relevance of information in the Redshift environment.
How to Use Salesforce API for Integration with Redshift?
Salesforce API is also a possible integration with Redshift. It is the most customizable method but also the most demanding in terms of the user skill level. Here, we would like to explain the basics of how a lot of the custom API integrations work in similar situations.
Accessing Salesforce Objects via API
Salesforce offers a multitude of API types for data interactions. REST API and Bulk API are some of the most common examples of such, with the former being responsible for small-scale real-time operations and the latter being at its best when working on large-scale data transfer tasks.
The first part of the data integration process is all about authentication via OAuth 2.0, obtaining an access token, and querying Salesforce objects to retrieve the necessary fields or records with the help of SOQL. A basic data extraction query should look like this:
SELECT Id, Name, LastModifiedDate FROM Account WHERE LastModifiedData >= YESTERDAY
Automating Data Export from Salesforce
These queries can be automated to a certain degree, but the automation process would have to rely on custom scripting in its entirety, including both authentication and data retrieval. Once the script in question is created, it can be automated using almost any job scheduler (AWS EventBridge is a good example).
There should also be a lot of freedom for customization in such scripts, such as different handling processes for specific data types, parallel processing, and so on. Some of the more complex requests can be made into a single process to reduce the number of API calls, and proper error handling to manage failed requests would reduce the necessity for constant human intervention.
Then again, the entire process of using custom scripting is highly sophisticated and relies entirely on the skill of the scriptwriter, with a near-infinite skill ceiling when it comes to potential optimizations.
Handling API Rate Limits during Data Transfers
The reason why API limits are mentioned separately in the section above is that most Salesforce APIs have strict limitations on the number of requests per org in a specific time period. Some of the licensing versions also have different API request ceilings, as well.
A lot of the custom integration scripts should be designed with API limitations in mind, including backoff strategies and request rate limiting. Try to batch your requests in bulk operations, implement exponential backoff when encountering rate limit errors, and think about using a queuing mechanism when it comes to exporting large datasets in order to prevent overwhelming the API.
How to Automate Salesforce to Redshift Data Loading with GRAX
Manual data loading is rarely useful outside of one-time migrations or infrequent data transfers, but performing them on a regular basis can be challenging and time-consuming, making it an unsustainable process. Using a third-party solution such as GRAX is a great alternative to any and all native processes, providing a solution that eliminates a lot of the tedious parts of the manual data loading sequence.
The Ability to Streamline Data Capture and Loading
GRAX can simplify the data-loading process through the ability to automatically capture the changes in Salesforce data in real-time. It can also work with custom objects and related records, making it a stark contrast to a slow and tedious manual data exporting via Data Loader or its alternatives. The automated nature of the process also ensures that no changes are missed while removing the need for any manual intervention into the data extraction sequence.
Data Pipeline Management with No Manual Intervention
GRAX’s automated pipeline for data exporting is significantly easier to work with than any variation of a manual process, removing the necessity to go through a multi-step process every single time. The platform can also handle data transformation, loading, and authentication on its own, dramatically reducing the amount of effort and maintenance necessary for every data export process, which saves time and resources for the business.
Historical Data Management
Another useful feature of GRAX in this department is its ability to maintain historical data versions for a designated time period, easily capturing and storing data changes over time. The number of organizations that require a detailed audit for compliance or analysis purposes is massive, making this particular feature a great addition to the repertoire of any business. The fact that the information is archived and not deleted makes it even better in hindsight, making sure that all information can be accessed in Redshift when necessary. This benefits the company in question due to the ability to not overextend existing data storage limits in Salesforce.
Want to take control of your Salesforce data?
Learn how GRAX can help you with Salesforce data protection
Common Challenges in Integrating Salesforce and Redshift
Now that we are aware of how difficult it can be to handle data integration processes manually, it should become significantly easier to understand why third-party ETL tools are often the preferred integration method in most situations, offering a combination of user-friendliness and convenience without a painfully demanding skill requirement.
Yet, data integration with third-party solutions might also have its own issues that vary from one solution to another, along with potential errors that might appear regardless of the chosen software. In this section, we would like to highlight the most prominent issues that might appear during or after data integration processes.
Data Format Compatibility Issues
Data type mismatch is surprisingly common for integrating Salesforce with Redshift if no data transformation processes are set up beforehand.
- Salesforce’s custom fields (picklists, formula fields) can’t map directly to Redshift data types in some cases.
- Compound fields (such as addresses), on the other hand, would have to be split into separate columns to be processed properly.
- Some text fields might exceed Redshift’s VARCHAR limitations.
- DateTime fields might be misaligned or otherwise problematic due to potential timezone misalignment.
- A lot of Salesforce default values might not align with the constraints of Redshift, and the same could be said for null handling (both require careful transformation processes).
Managing Data Security and Compliance
Considering the sensitive nature of most information in Salesforce, it is only natural for security considerations to be a factor when it comes to transferring said data to another location.
Compliance is an important element here, ensuring the absence of issues with GDPR, CCPA, or any other industry-specific regulation. Data encryption is a standard feature for such processes at this point, with AES encryption being used at rest and SSL/TLS protocols protecting information mid-transit.
Configuring access controls with policies and IAM roles should prevent many instances of mismanagement of access, and access to detailed audit logs should simplify issue resolution without threatening the aforementioned compliance breach.
Additionally, all these measures should also be reviewed on a regular basis to ensure their working state, authenticity, and potential upgrade paths.
Troubleshooting Connection Problems
Data integration is a field that is familiar with all kinds of issues, and it relies a lot on systematic debugging to be able to resolve anything in the first place. Some of the most common issues with integration are:
- Network connectivity issues
- Authentication failures
- Timeout errors
A lot of these basic issues are relatively easy to resolve with careful API response monitoring, timely access token renewal, and so on. Automated alerts and comprehensive logging would also help with a lot of the troubleshooting issues down the line.
Additionally, data consistency during integration would benefit a lot from proper retry logic and several fallback mechanisms so that the data integration processes are not terminated completely unless the issue is extremely large and unmanageable.
What are the Best Practices for Salesforce to Redshift Replication?
Aside from some issue resolution methods we went over above, there are also numerous other recommendations and best practices that can be used to simplify the data integration process between Salesforce and Redshift or improve its total performance. Here, we are going to try and prioritize recommendations that were not mentioned before.
Data Replication Strategies for Large Volumes of Data
When it comes to large datasets in Salesforce, the correct replication strategy is as important as anything else. Full data replication is recommended for initial data loads, followed by incremental updates of the environment.
Large volumes can be processed more easily with a queueing system, and the support for the aforementioned COPY command in Redshift would greatly optimize data ingestion due to the incredible performance of parallel loading. Additionally, a particular approach called “slowly changing dimension” should simplify the tracking process for historical changes.
Ensuring Data Integrity during Integration
Basic error handling is not the only matter that needs to be addressed during and after data integration. Data integrity is just as important here, necessitating the usage of checksums, atomic operations, data validation rules, and reconciliation dashboards.
The goal of all these efforts is to ensure that the information remains consistent and complete both in Salesforce and after it has been integrated into the Redshift environment, with all of the data validation rules and key metric comparisons to ensure their complete state.
Monitoring and Managing Data Loads
Monitoring is one of the key recommendations that can be offered to practically any data-oriented environment, and Salesforce’s integration with Redshift is no exception. Comprehensive monitoring systems with AWS CloudWatch metrics should provide sufficient information about the data at any point in time, and the tracking of key performance indicators would provide a simple way of detecting whether there’s anything wrong with the process, to begin with.
Customizable automated alerts for problematic events such as performance degradation and failed loads should reduce the necessity of manual control over the integration process, and automated reports would be an easy source of information when it comes to analyzing historical patterns and identifying long-running issues.
Additionally, modern data integration platforms like GRAX can also assist with monitoring tasks like this with purpose-built dashboards and customizable alerts. They can not only work with basic metrics but also many unique patterns that are specific to Salesforce, finding potential issues in the environment early on and providing better visibility over the entire data pipeline from start to finish.
How to Connect Redshift and Salesforce?
Discover GRAX for Salesforce data integration
Conclusion
Integration of Salesforce with Amazon Redshift is a powerful combination of data management and analytical capabilities, and there are multiple integration methods to choose from. With that being said, both manual and built-in integration methods are way too case-specific to be useful outside of a few unconventional situations. Additionally, some of these methods are also far too complex for most users to even consider (such as API-based integration).
In this context, third-party ETL tools would be the best possible option for data integration with Redshift, providing substantial functionality without making the integration itself as complex as in other methods. Specialized software such as GRAX belongs in this category, too, providing a variety of capabilities that are far easier to manage than their built-in counterparts.
Take Control of your Salesforce Data Now
See GRAX data management solutions in action
Regardless of the integration method chosen, there are quite a lot of considerations that have to be kept in mind when attempting to integrate information into Redshift’s data warehouse – including data security, careful monitoring, detailed logging, extensive compliance, etc. A clear understanding of all these nuances and their potential shortcomings would make it easier for organizations to make informed decisions when it comes to integrating Salesforce with Redshift, creating a strategy that fits their company the most.

