Every business talks about being data-driven. But when it comes to accessing critical data for analytics and other purposes, it hasn’t been easy. The move to the cloud made it even more challenging.
It’s more important now than ever to understand what the challenges are so that you can overcome them and get the most value from your historical data.
In this whitepaper, you’ll learn about:
Key technical and economic reasons driving SaaS data access difficulties
How backing up data in a cloud data lake provides an ideal data hub for secure, flexible access
The implications of a data ecosystem comprised of historical data sets on business evolution
How to apply these learnings to Salesforce data management and reuse
Let’s face it; as critical as data is for business success, it has always created a myriad of problems. It cost so much to store in the early days that you had no choice but to minimize the amount of data you kept. This meant that vital historical information was often rendered unactionable or just simply lost. Fortunately, as the cost of data storage shrank in sympathy with Moore’s Law, it fell far beneath the point where storage costs were a primary concern. Instead, the main challenge transformed into getting access to data when you needed it, in the form you wanted.
The move to cloud storage provided excellent opportunities for IT to reduce hardware costs and increase deployment speeds, but it has done little to make data access easier. In fact, instead of your data just being fragmented across a data center, it is now also fragmented across multiple clouds: Amazon, Azure, Google, and others—in databases, data lakes, and file systems—and across the many SaaS applications that inhabit the cloud.
What organizations need, and no doubt yearn to have, is a single unified data fabric. We can characterize such a data fabric in the following way:
“The business can get at and make productive use of all its data, current and historic – not just the data its systems have created, but also data in all SaaS applications and imported from elsewhere.”
That’s a big ask.
The Data Access Issue
Copy link
The Data Access Issue
The Data Access Issue
Let’s consider the difficulties of data access, which are more significant with cloud-based SaaS software.
Nowadays, almost all organizations use SaaS products for some of their mission-critical business applications, such as those offered by Salesforce, SAP, and Oracle. Financially, it is usually a sensible move. However, it means that you have no direct control over your data generated in and flowing through those applications. Instead, direct data access is achieved through API calls.
SaaS providers have their technical and economic priorities. They may have tens of thousands of subscribers. They may need to support many millions of API requests every second. So, naturally, they manage this traffic by constraining it in some way. They might, for example, limit each user to a fixed number of API calls in a given time span, say, 1,200 every 120 seconds. If the subscriber exceeds the limit, the API calls are either delayed or incur an overage charge for the resource usage. It’s how you would expect them to behave when you think about it.
Nevertheless, it means that unless you have a well-thought-out approach to data access, it will cost you—either in software performance or hard cash.
Back-Up as Foundation Stone of an Integrated Data Ecosystem
Copy link
Back-Up as Foundation Stone of an Integrated Data Ecosystem
Back-Up as Foundation Stone of an Integrated Data Ecosystem
Consider now the general idea of a data fabric. Think of the corporate IT resource as consisting in part of a collection of interactive systems that need to be backed up for the sake of resilience. In every case, there will be a well-honed recovery process that depends on backup files. Similarly, the IT resource will include a collection of BI and AI applications that feed on the data of these business systems.
Examine Figure 1 below.
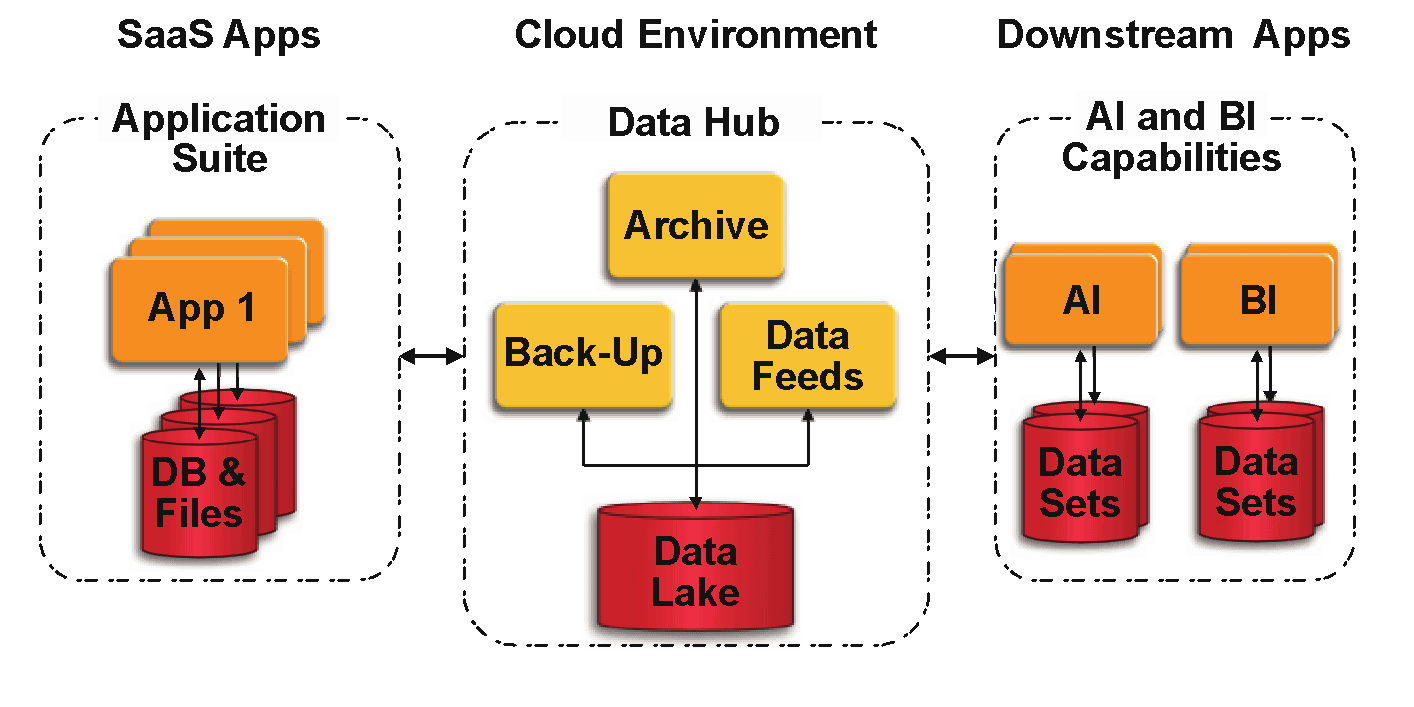
Figure 1. A Strategic Back-up-Based Data Hub
First, let’s consider a single application suite like Salesforce. Although the SaaS vendor offers a data backup service, it is usually minimal and unlikely to be well-suited to your needs. This is certainly the case with Salesforce. That’s why its AppExchange includes several alternative backup apps, indicating that data backup is a capability it is happy to leave to other 3rd-party vendors.
The data from such a set of applications needs to be correctly backed up, and the backup needs to go hand in hand with a data archiving capability. That is a simple matter of economics.
You don’t want to pay your SaaS vendor to store data that you are no longer using online.
And importantly, if you keep a complete data backup of your SaaS-based application suite, it can also become the foundation of a data hub that has at least three useful purposes: backup, data archive, and data feeds to downstream applications — all the apps that can make use of the data, including, of course, BI and AI apps.
In the absence of such a data hub, a difficult-to-manage-and-maintain web of ETL and API access paths will inevitably develop. With a data hub concept, the backup software becomes the data ingest application for the hub. If it implements a “change data capture” approach to gathering data, there will be a minimal time lag between the live applications and the data backed-up.
This creates a similar situation to in-house applications that, for resilience reasons, have a “hot standby” database. Typically, because the hot standby is rarely called into service, its data is made available on a read-only basis to BI and analytics applications.
The Data Structure Imperative
Copy link
The Data Structure Imperative
The Data Structure Imperative
It may not have escaped your notice that we indicate a cloud data lake as the data store for your data hub in the diagram. It has taken time for data lake technology to mature. Still, now that it’s possible to have read/write/update capability, data lakes are preferable to databases for data hub workloads. The point about data lakes is that they are far more flexible in respect of data structures.
Just as important, they live in cloud environments that you, rather than your SaaS vendor, essentially own, whether it’s in AWS, Azure, or other cloud infrastructures, so that you can better control who can access it in the first place and make it readily available for analytics and other downstream processes.
The data from a particular set of applications might need to be fed into a time-series database, graph, No-SQL, lightning-fast relational, or even another data lake. A data lake is the most flexible storage vehicle to cater to that. We are suggesting, then, that the backbone of a data fabric should be a network of interlinked data lakes.
One of the awkward facets of business applications, SaaS or otherwise, is that their data is structured and optimized for the application’s transactions. The data is neither designed nor structured for the other applications that need to use it downstream. In particular, because such applications are transactional, they tend to ignore the dimension of time and the optimal structure for historical data.
One of the functions of the data hubs we describe here is to “normalize” the data to effectively serve any other application that may need to use it. Particularly, if it stores transactions as a time series, it lays the foundation for BI applications based on historical data. In fact, it is in a position to allow for any new kind of BI or AI application that may evolve.
The critical point is that a data fabric of the type we describe is necessary to gather such historical data and organize it coherently.
The Cycle of Action-Analysis-Knowledge-Knowledge Application
Copy link
The Cycle of Action-Analysis-Knowledge-Knowledge Application
The Cycle of Action-Analysis-Knowledge-Knowledge Application
In overview, the evolution of a business occurs by a cycle of business activity, followed by an analysis of the outcome in the context of the company’s history, followed by innovation based on the knowledge gathered.
If we translate that into IT activity, transactional systems create data that is served up in an appropriate form to BI and AI apps. These either generate knowledge under their own steam or enable business staff to generate knowledge. Finally, that knowledge determines the behavior of business staff and applications in evolving the business.
If you think of it in those terms, it becomes clear that a data ecosystem comprised of historical data sets that go back as far in time as needed is required to support this natural business evolution.
SaaS applications can pose a limitation, mainly if the data they preside over is difficult to access and reuse. There are very few software services that can help with this. One that can goes by the name of GRAX.
How Can GRAX Help?
Copy link
How Can GRAX Help?
How Can GRAX Help?
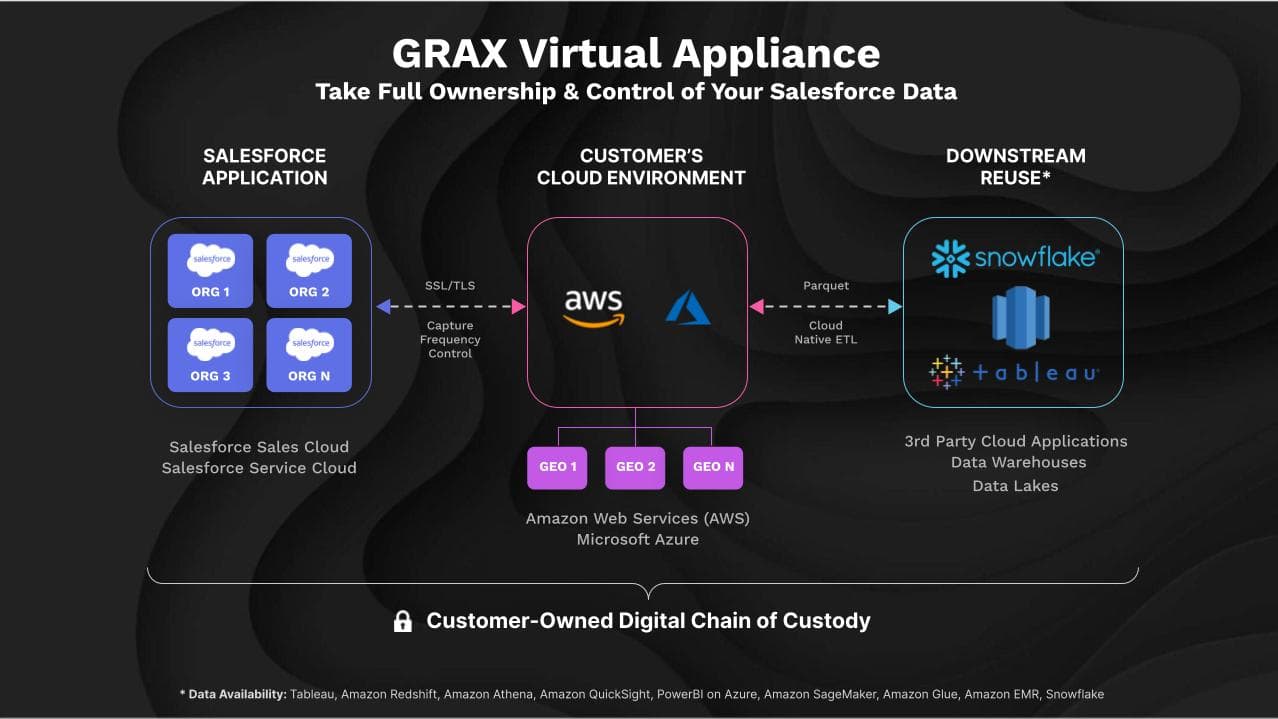
GRAX provides a data hub capability (they refer to it as a data platform) of the kind we have discussed, currently focused on the Salesforce suite of apps. In our view, its architecture is impressive enough to examine if you are currently working to create or maintain a data ecosystem. Moreover, from the SaaS subscriber perspective, the GRAX data platform is straightforward to use. The technical complexity is all “under the hood.”
In the Salesforce environment, GRAX captures an irrefutable, recoverable record of up to every single change that happens to data, stores it all elsewhere in the customer-owned cloud, and is available when needed. It is a cloud architecture.
As GRAX does not provide its own cloud service, users can bring their own cloud provider they prefer for storage (AWS and Azure are currently supported). GRAX will deploy a virtual appliance in the chosen cloud environment and backup/archive their historical Salesforce data directly into the customer’s cloud data lake, where it enables quick access to downstream cloud apps—no coding required.
GRAX provides read/write data lake capability based on Apache Parquet, making it a fully updateable data store. This provides it with the ability to support the data hub functionality we have described. Additionally, GRAX provides the ability to be an active data source for a complete data mart of historical SaaS app data used in analytic databases, such as Snowflake, the best-in-class MPP analytic database, in this role as well as for the full range of AI and BI applications.
It also supports downstream processing throughout the cloud provider’s ecosystem, such as Amazon Athena, Amazon EMR, Amazon QuickSight, Amazon Redshift, Amazon SageMaker, and AWS Glue. Taken together, these Amazon capabilities provide an important, complementary set of data access, data processing, data transformation, and data analysis use cases.
GRAX also supports the front-end analytic tools Tableau and PowerBI by Azure for analysis, data exploration, data discovery, and experimentation.
If you are a Salesforce user looking to get greater value from your historical data and build out an effective data ecosystem, take a look at GRAX.
About The Bloor Group
Copy link
About The Bloor Group
About The Bloor Group
The Bloor Group is a hybrid Media / Analyst firm focused on AI, Analytics, Big Data, Cloud Computing, and related technologies. Since 2010, we have served more than 200 of the most innovative software vendors in the world. As purveyors of #DMRadio and #InsideAnalysis, we are the only Analyst firm with coast-to-coast radio shows in the USA. Contact us at info@bloorgroup.com.
Please wait while our meeting scheduler loads to pick a time to meet with us...
Cookie Policy: This website stores cookies on your computer. We use cookies to personalize content, ads, and marketing efforts, and to analyze our traffic. Some of these cookies also help improve your user experience on our website. To find out more about the cookies we use, please review our Privacy Policy.